All you need is text. Plain text (almost).
As many of us, I built my first documents writing and presentation (slides) creation skills with the Microsoft Office. And as for many of us for me “document” meant something, written in the WYSIWYG1 type of editor: Microsoft Office Word, LibreOffice Writer, StarOffice, etc.
And as many of us I was doing the same logical mistake: in my mind both format for text storage and format for text presentation were the same.
But in the last few years I have been changing my view on the documents creation, text writing and text presentation. It all merged into one principal:
Text information must be stored in the plain text files. Or as close to plain text as possible.
While many of my university mates were using LaTeX for writing their works, I found LaTeX overcomplicated and confusing. Also, there many flavors of *TeX and compilation of the source file requires knowledge of the particular LaTeX flavor, its modules and differences in the programming syntax.
In my fear of this complexity and my laziness to learn LaTeX I had been sticking to the WYSIWYG editors till about 2 ~ 3 years ago.
My discovery of Markdown
About 3 years ago I got the new role in the very interesting project, where most people are DevOps engineers and they use daily GitLab to collaborate and GitWiki to present documentation. Most of the content produced by them is different code, whether those are scripts, configuration files or even documentation they put on the GitWiki or convert into PDF. And that simple (but enough for 99% of cases) formatting of the text is done with Markdown.
I have to collaborate with different teams and my role is not only to write papers by myself, but also stimulate other creators to contribute and write some content into the documents. I wanted to keep GitLab as our main collaboration platform and I had to learn how to treat documentation content as code.
I had to learn what Markdown is and how people use it and how do they create different documents from the Markdown sources: PDFs, web-pages, Wiki-pages, Microsoft DOCX files, EPUBs, etc. And this was eye opening experience which changed my view on the content creation.
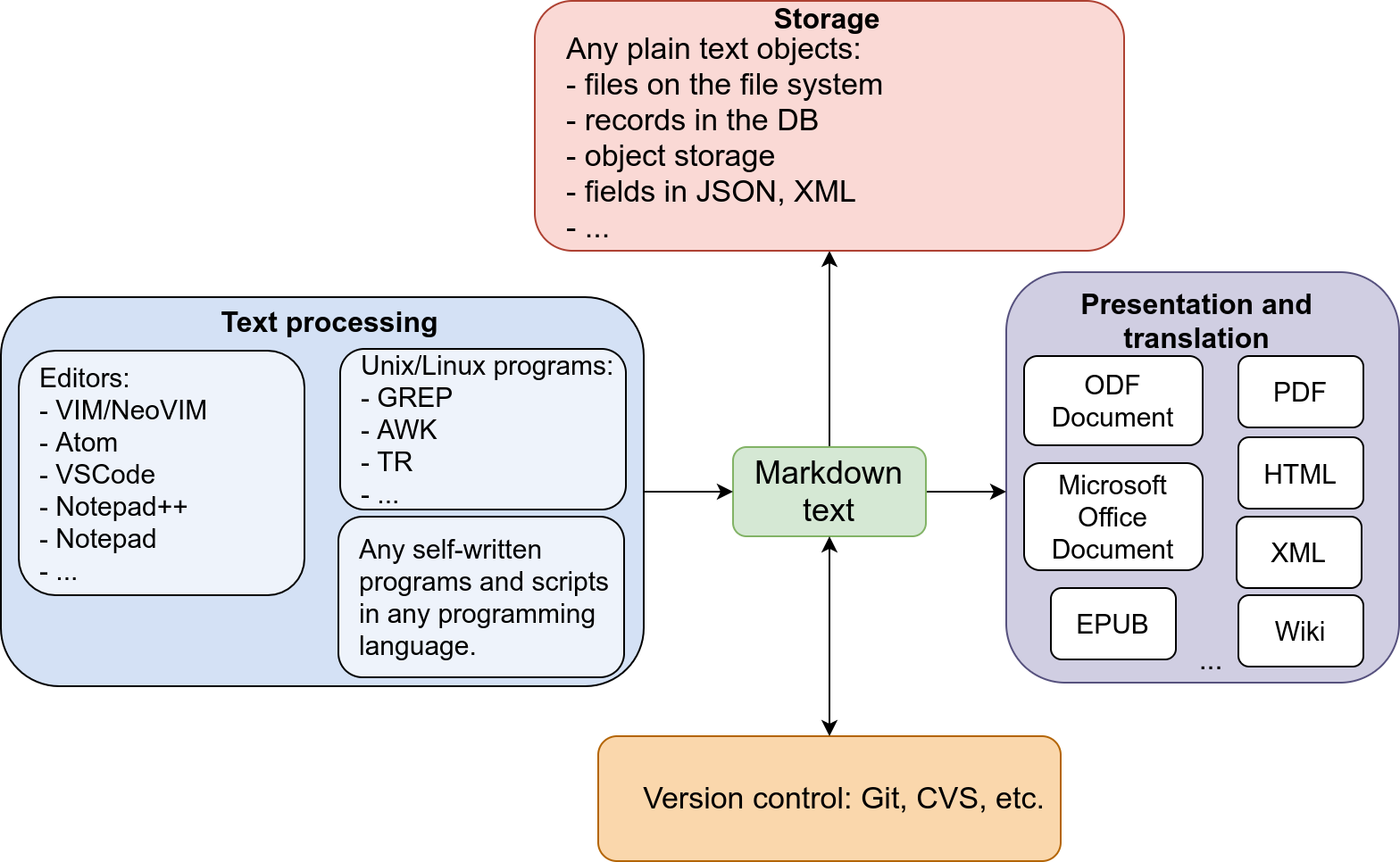
Data and presentation are not the same
I am a networking expert in my first area of expertise and in my previous job I spent plenty of time in studying and teaching others TCP/IP and OSI models. And I got used to layered nature of the communication technologies but somehow I did not wrap my head around to apply similar view to the text data. But after I learned Markdown and tool set around text transformation finally got it.
We don’t need to keep content in the presentation layer. I would say, in most cases we don’t do it at all. E.g.:
- Almost all programs written in the high level programming languages are just a text of instructions written in the special language. Then this text is compiled for execution (e.g. C++, Golang, Rust), or just interpreted on the fly and executed (e.g. Java, JavaScript, Python).
- Web is more complex now, but in the most cases Web-page with the formatted text on it is just a source text wrapped into HTML syntax (called “tags”) and processed and presented by the browser.
De-coupling text from its presentation makes many things simple.
Storing and maintaining text data
But we cannot store plain text because it is hard to present it later in some more fancy way. And this is where Markdown helps:
- Markdown is just small additional syntax for plain text files which then can be used by any processing software and which will convert it into the necessary presentation format (or maybe just another text storage format like HTML, XML, EPUB).
- Markdown text is readable without any special program. You can use any plain text editor you like. You can write Markdown files in the terminal, without using any GUI (this is how I do it now).
Benefits of the Markdown as text data storing format:
- It is open and cross platform (because it is a plain text).
- Lightweight. Markdown is like a plain text and consumes very little space.
- Any plain text editor works: VIM/NeoVIM, Nano, Notepad++, Atom, etc. etc.
- Linux/Unix native tools like AWK, GREP, WC, etc. can be used for search, replacement and other text modifications.
- Can be used with any software version control system (e.g. Git, CVS).
Presentation and transformation
Linux community has many powerful tools for transformation and conversion of different text based formats into: other text based formats and different presentation formats.
I can point out on the tools I use and I found the most universal:
- Pandoc: The most powerful program for text conversion and presentation. I use Pandoc to produce from the Markdown files: PDF documents, ODT documents, DOCX documents and presentations in the PDF “beamer” format.
- Hugo pages: Static web-site generator. Uses Markdown as source files.
I have made my Github projects where I share my scripts and Gitlab CI-pipelines with others:
Benefits of separation
I would like to point out on number of benefits from the separation of data from its presentation format:
- Presentation format consistency. My text changes do not influence output formatting and visa versa.
This is hard to achieve with MS Word Document format. When document is edited by many people, then formatting and styling turns into a mess.
- I can have multiple output files for the same input text:
- Different page sizes, cover pages, different font sizes, DPI settings, protection settings, etc.
- I can use scripts, CI pipe lines for end-documents generation.
- I need to store only source text and images. I do not need to store files in the presentation formats (PDF, DOCX, etc.). I can generate them any time I want.
- I can use any text indexing and search software, starting from the simple text search using GREP tool and up to any indexing program.
- For the indexing program I do not need any special modules and plugins for the binary and proprietary formats like PDF, DOCX, etc. I need plain text search only.
- I can merge/split documents easily without fear to break them and their formatting.
These were my 6 main benefits of separating data and presentation layer and keeping original text in the Markdown format.
There is no one size fits all
While I like Markdown and I pointed out to the benefits of this approach, I agree that it does not fit all. It requires certain amount of skills and mindset:
- Ability to understand the difference between data and its presentation.
- Ability to treat your data as a code:
- Organize and maintain files in the proper structure.
- For the best benefits use version control system like Git (GitLab, Github, Gitea,…).
- Learn Markdown.
- Write your own scripts or have people who can write them for you.
I believe that this approach (splitting data and presentation of data) is useful for a long term documentation creation process which requires consistency of the output format.
But for a quick and simple cooperation and document creation MS Office 365 or Google Docs are also right choices.
-
What You See Is What You Get. ↩︎